Data Sampling Tutorial
In this tutorial we will use the Waste sample network, which is included with Bayes Server, to demonstrate how to use Data Sampling to generate sample data from a network.
Accompanying video
No evidence
- Open the Waste sample network included with Bayes Server, either from the Start Page or from the File menu, click Open.
The Waste network with no evidence set should look like this...
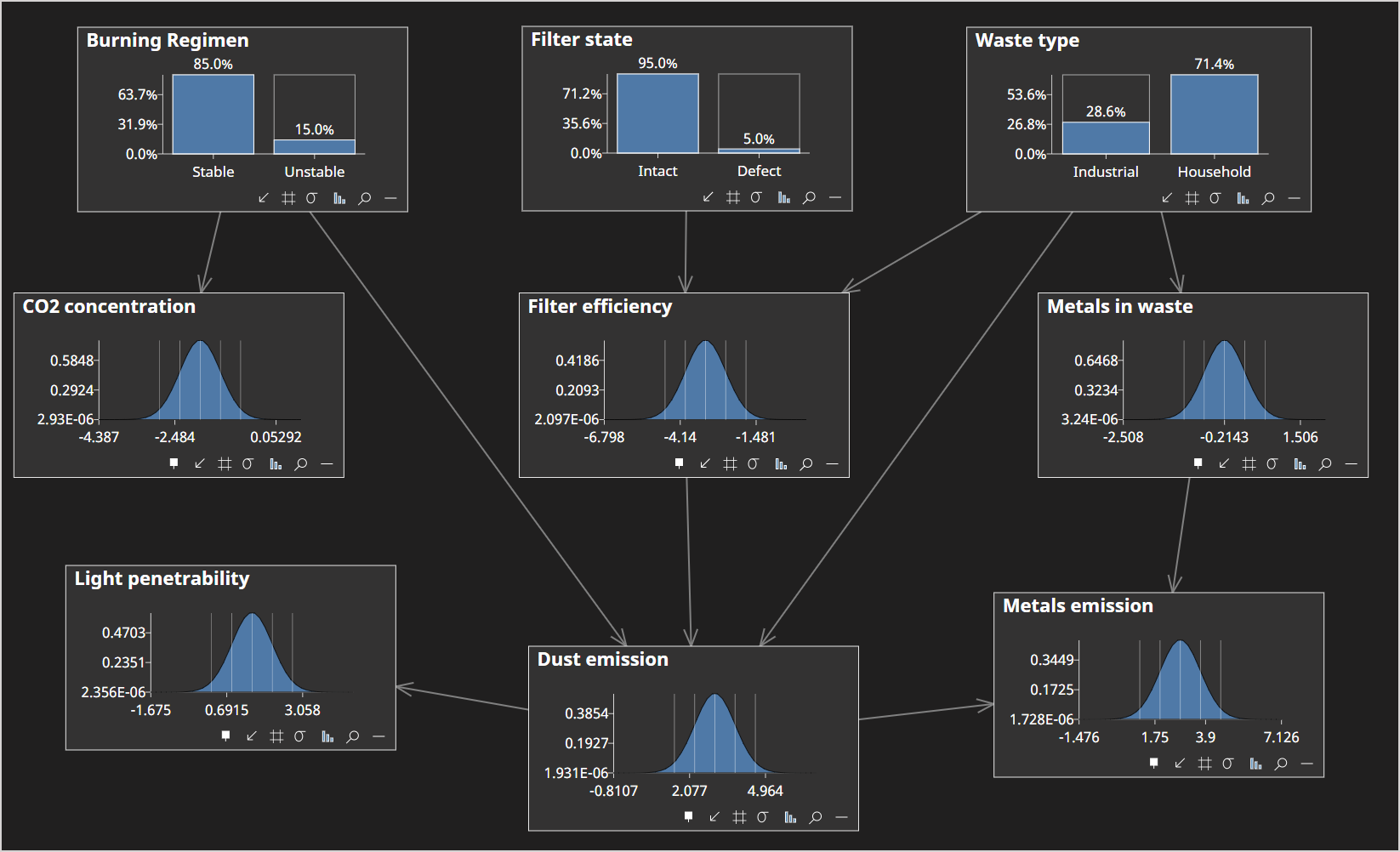
When we sample data from a network, we can either have no evidence set, or we can consider existing evidence, such that each sample will have exactly that evidence subset set.
- From the Evidence menu, click Sampling.
We will initially leave the options in the default states, which should look as follows:
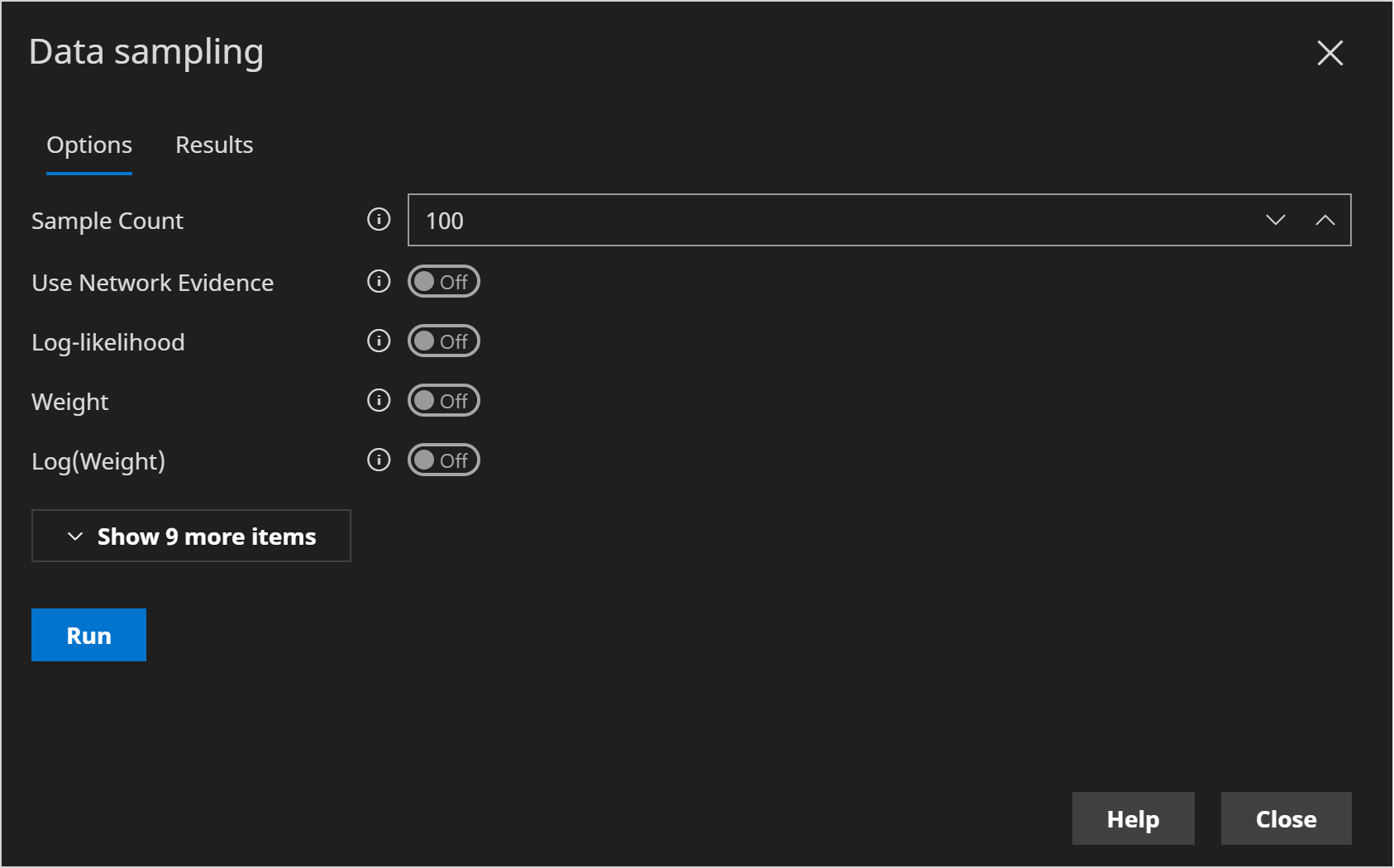
- Click Run.
Since we haven't set a Seed (one of the Data Sampling options), the results will look different each time, however will look something like the following:
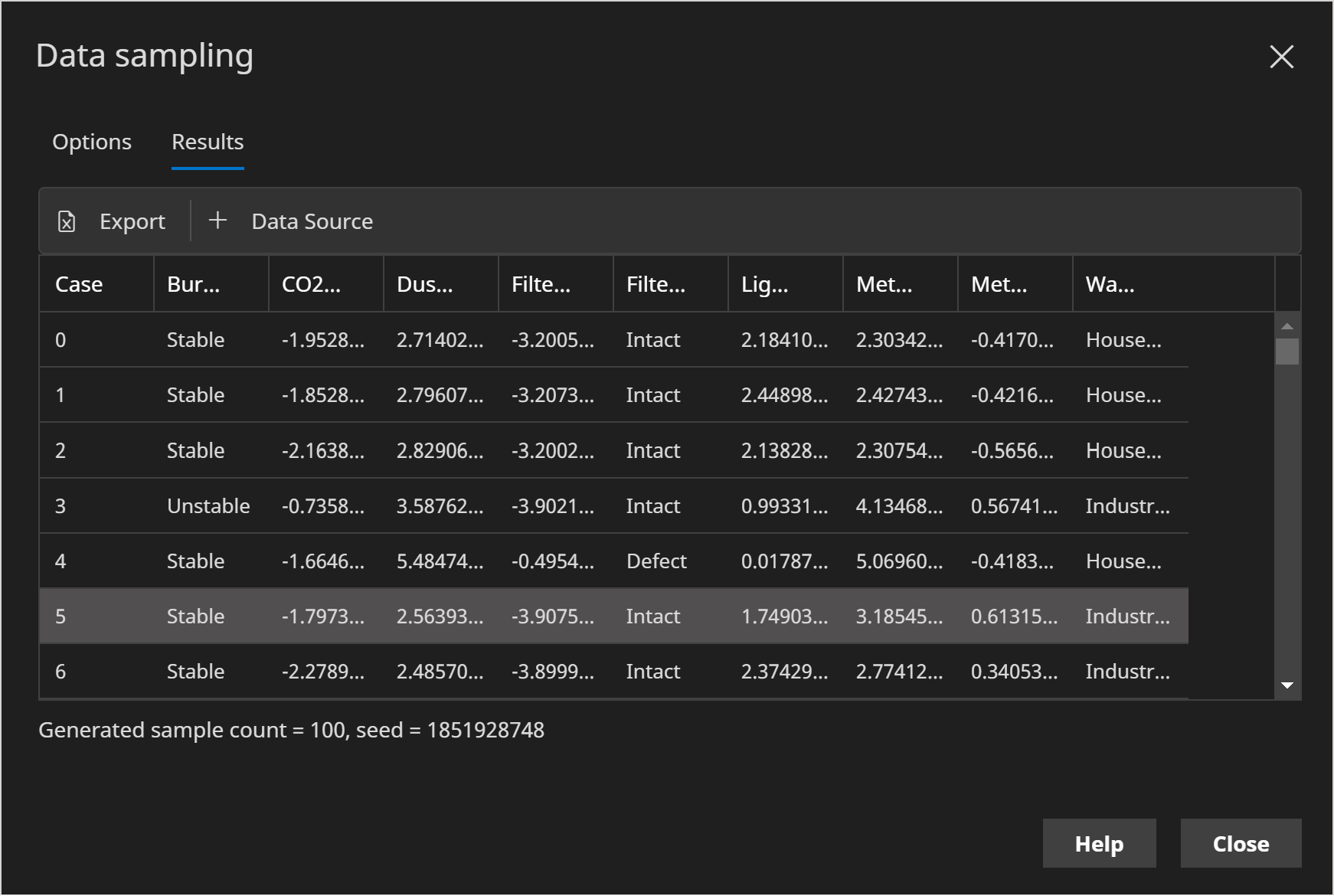
At this point we have the option to export the samples to a file, or add them as a temporary data source to use in subsequent analyses. The latter is extremely useful for ad-hoc experimentation, however for reproducibility you may prefer to save to a file and load that as a data source which will persist between sessions.
For more information on how these samples are generated see Data Sampling.
Existing evidence
We will now see how sampling works with existing evidence.
Close the Data Sampling dialog.
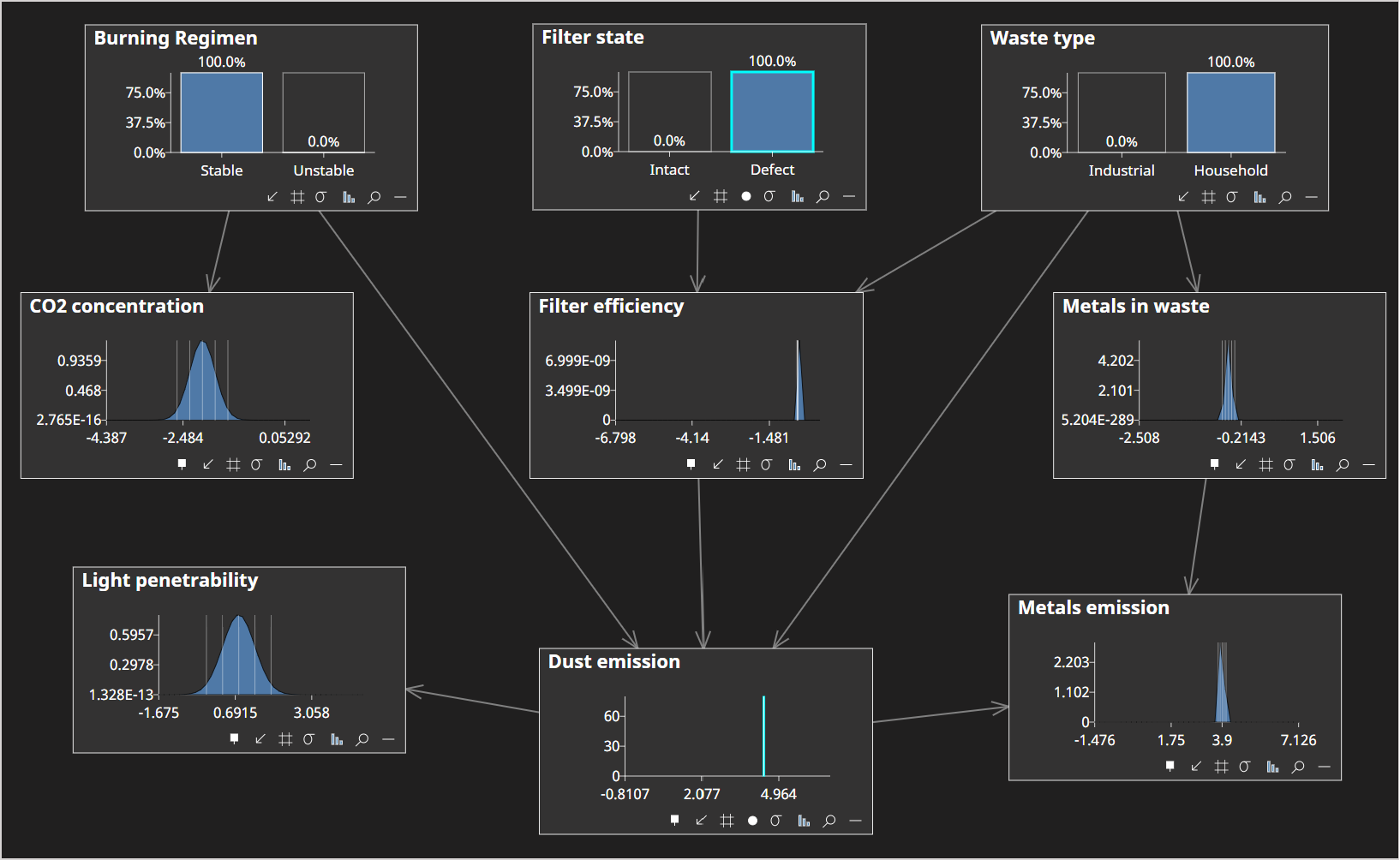
Set the following evidence by clicking on the node chart:
- Filter state = Defect
- Dust emission = 4.4
The network should look as follows:
From the Evidence menu, click Sampling.
Turn Use Network Evidence to True
Turn Log-Likelihood to True
Turn Weight to True
Turn Log-Weight to True
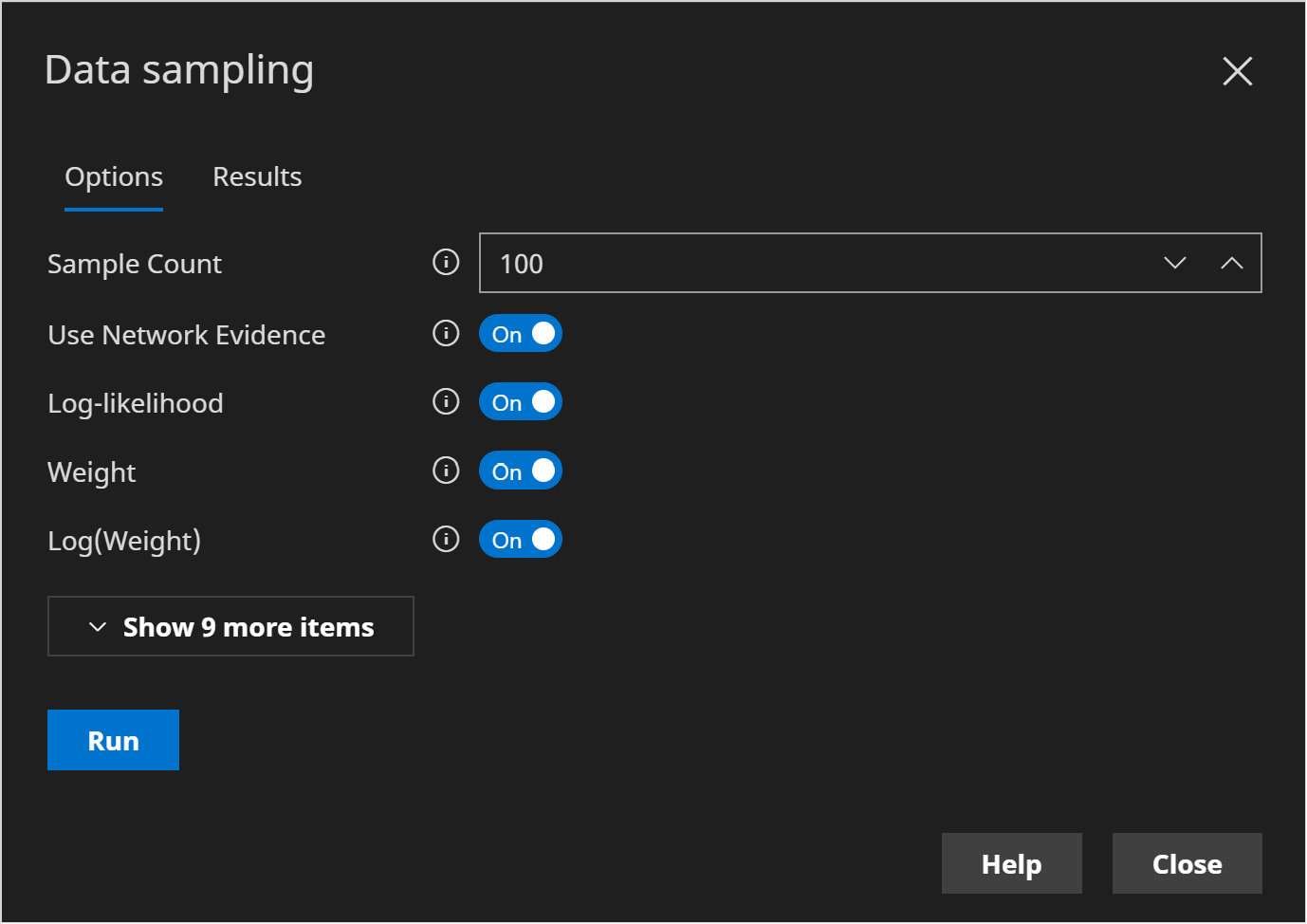
- Click Run
Since we haven't set a Seed (one of the Data Sampling options), the results will look different each time, however will look something like the following:
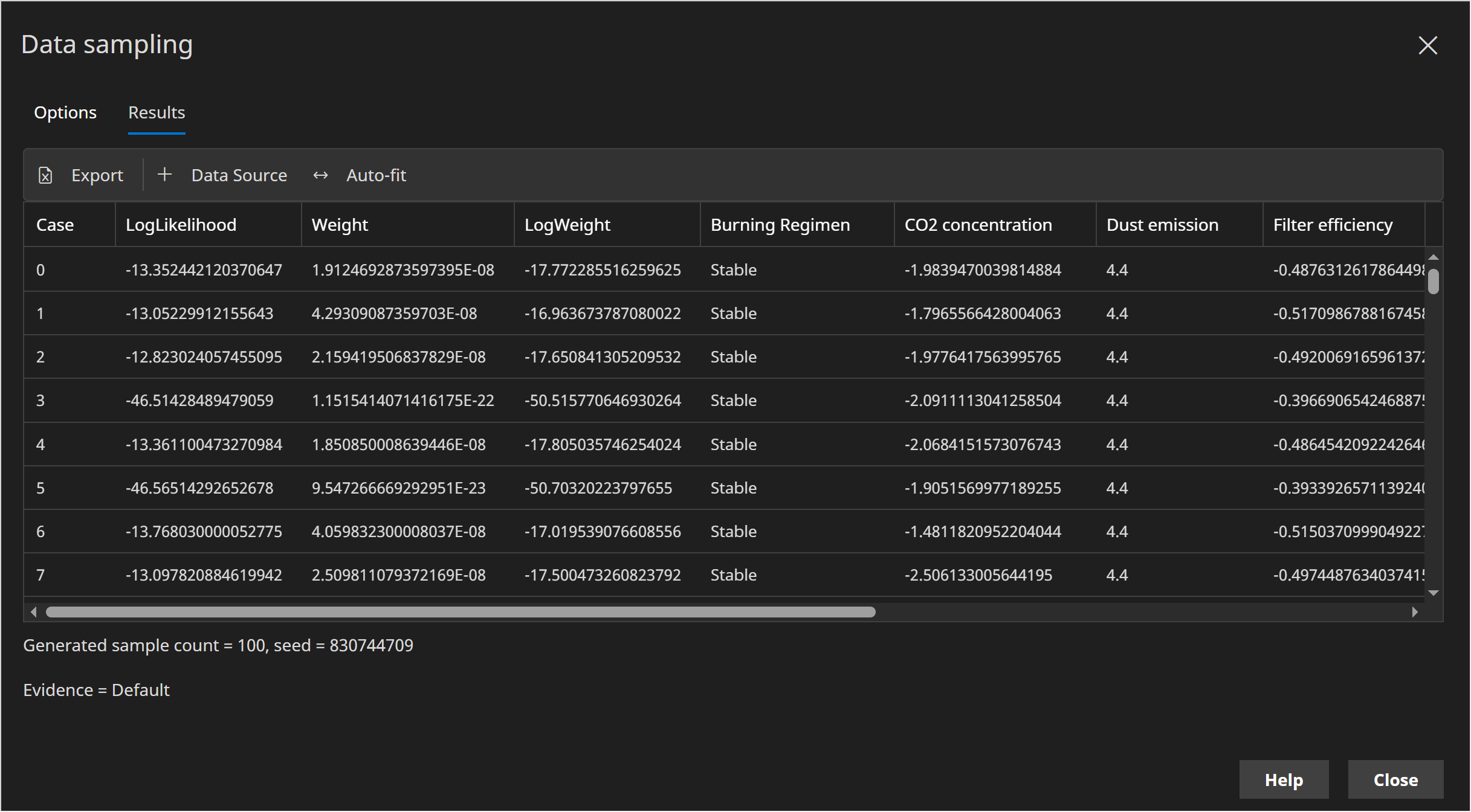
- Verify that each sample generated has the following evidence set:
- Filter state = Defect
- Dust emission = 4.4
When we have existing evidence set, it is often useful to output the Log-Likelihood of the row, as that tells us how likely (anomalous) that case is.
When evidence is fixed, each sample has an associated weight, which is the likelihood of the fixed evidence for the current sample. This indicates how likely it is that the fixed evidence could have occurred with this sample. We decided to output the log-weight in addition to the weight this is more robust to underflow.
For more information on weight and log-weight, including how they are calculated see Data Sampling.
Missing data
We will now see how sampling works when we want to generate samples with missing data.
Note that the missing data mechanism used is Missing Completely At Random (MCAR).
Bayes Server has extensive support for inference, parameter learning and structural learning with missing data.
Close the Data Sampling dialog.
From the Evidence menu, click Clear
From the Evidence menu, click Sampling.
Click the Show more (x) items button
Set the Missing Data Probability to 0.1 (which is 10%)
The options page should look as follows:
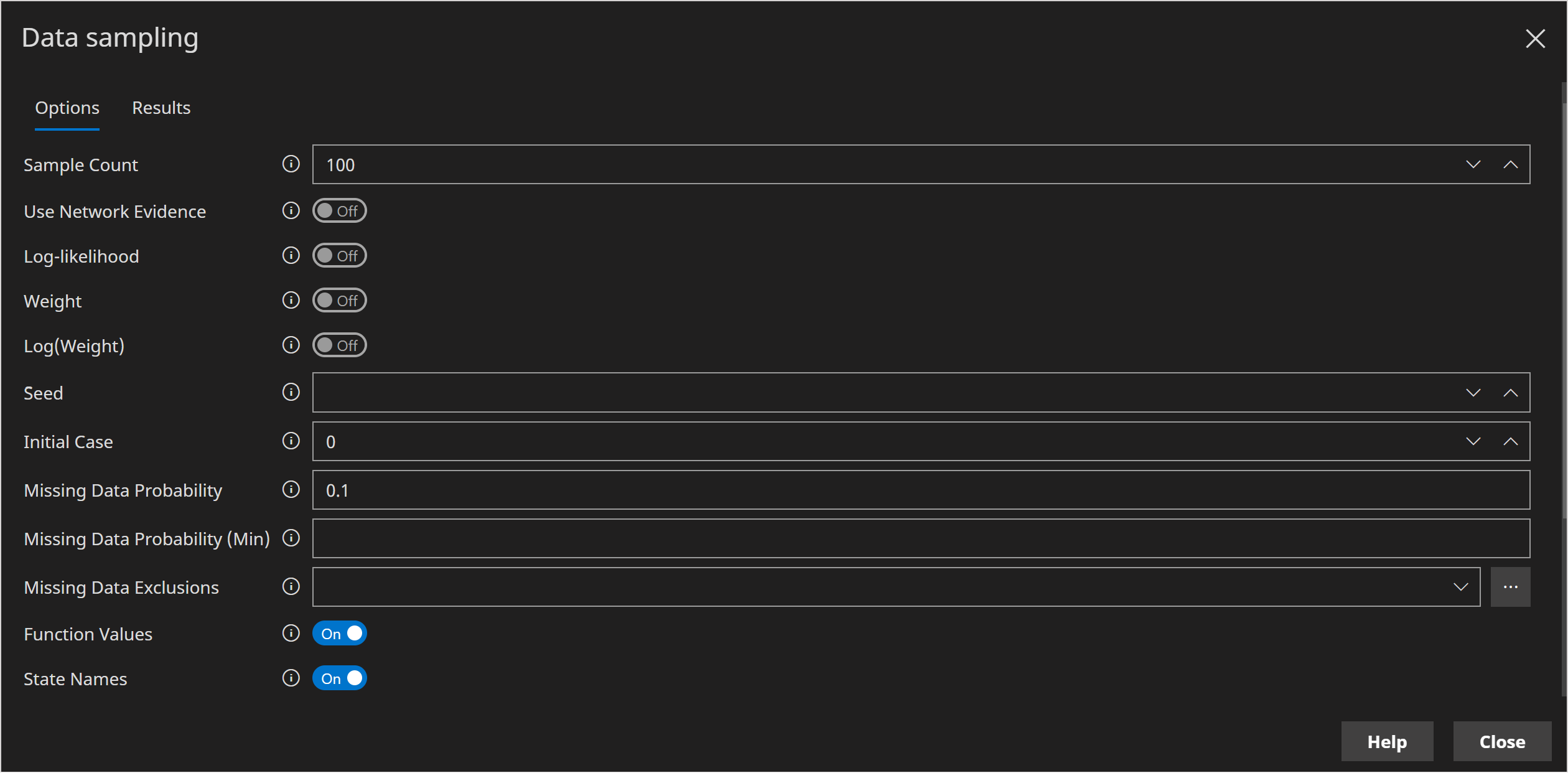
You can use the Missing Data Exclusions options to limit missing data to certain columns.
- Click Run
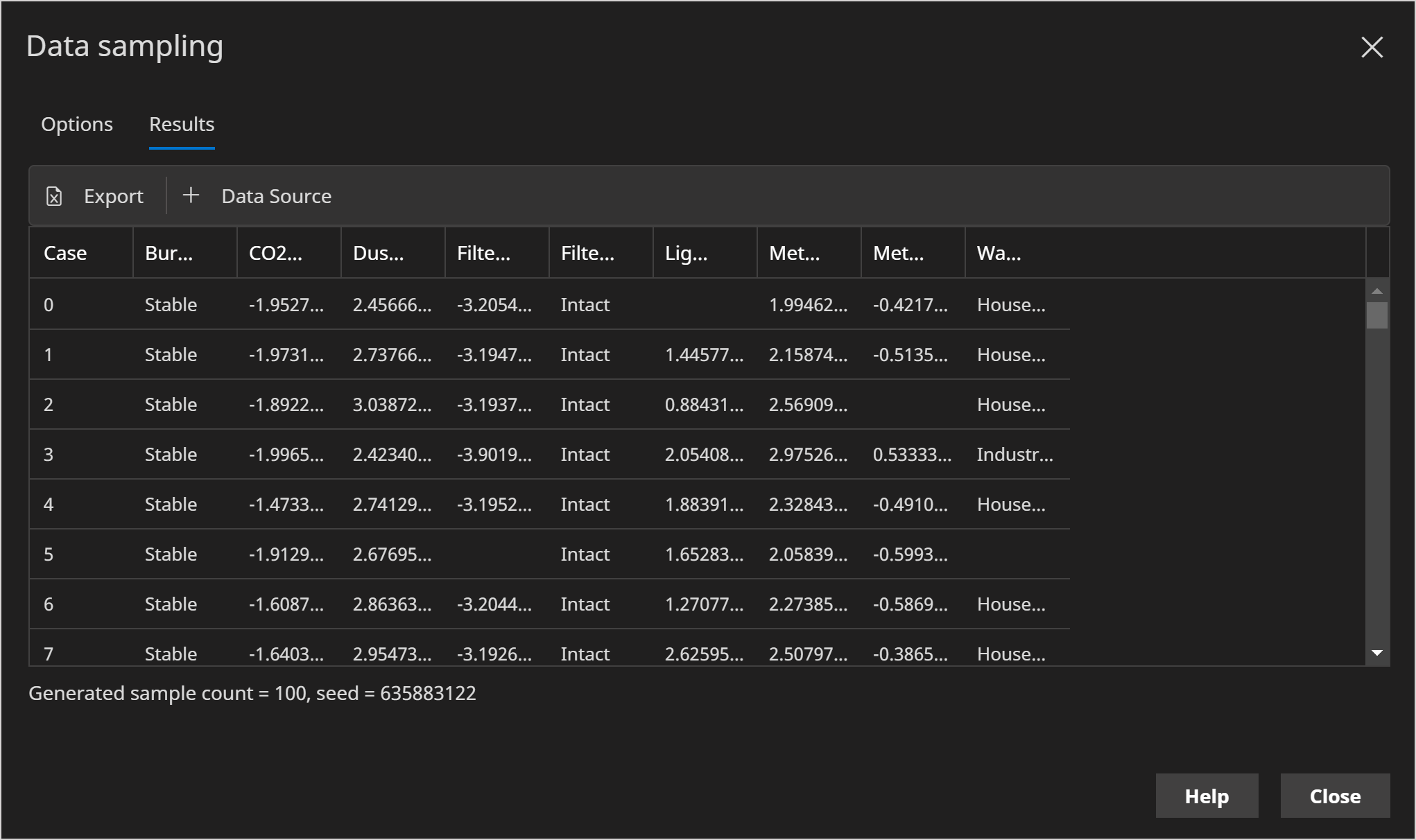
- Verify that some data is missing/null.
Data with missing values is important to study how different algorithms handle missing data robustly, which Bayes Server does.
At the bottom of the dialog you can see what seed was used for generation (if you specified a seed, this will be the same). you can also see how many samples were generated. This is typically the number of samples you requested, but may be fewer if there is missing data and inconsistent evidence occurs for some samples.